
 Častý problém při analýze dat je, že výzkumník má tendenci vidět vztahy, které v datech nejsou („tady je jasná závislost, to nevadí, že test nevyšel významně“). Správným přístupem je předregistrace a spoléhání na statistické testy. Druhou možností je použít metody z oblasti visual inference statistics předtím, než se výzkumník přímo zanoří do dat.
Častý problém při analýze dat je, že výzkumník má tendenci vidět vztahy, které v datech nejsou („tady je jasná závislost, to nevadí, že test nevyšel významně“). Správným přístupem je předregistrace a spoléhání na statistické testy. Druhou možností je použít metody z oblasti visual inference statistics předtím, než se výzkumník přímo zanoří do dat.
Obecně metoda funguje následovně: Z naměřených dat se vytvoří několik grafů, ve kterých jsou data vybraná náhodně za předpokladu, že není mezi daty žádný vztah. Tyto grafy se seřadí vedle sebe a namísto jednoho z nich se schová originální graf. Pokud pozorovatel správně pozná originální graf, lze to brát jako jeden z důkazů vztahu mezi proměnnými. Tomuto způsobu se říká lineup protokol, jelikož připomíná stejnou metodu, která se používá při identifikaci pachatelů. V jazyce R je pro tyto účely specializovaný balíček nullabor, který umožní na pár řádek kódu generovat podobné grafy.
V následujícím obrázku vidíte ukázku přesně takového lineupu. Poznáte, která korelace je originální? Data se týkají testů aut z roku 1974. Na ose x vidíte počet ujetých mil na jeden galon a na ose y je váha auta. (Správná odpověď je na konci).
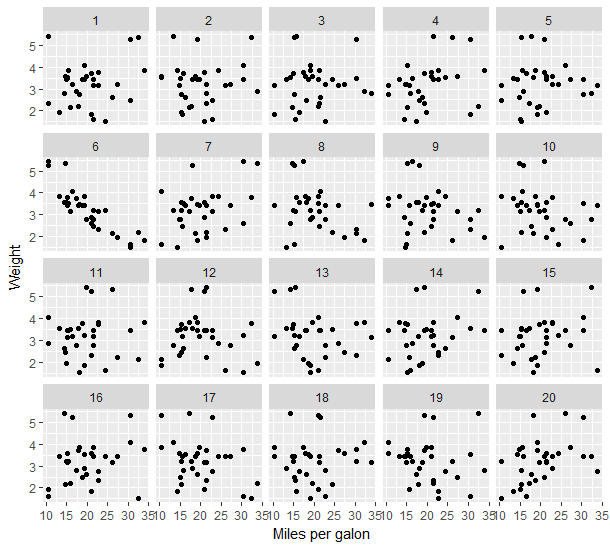
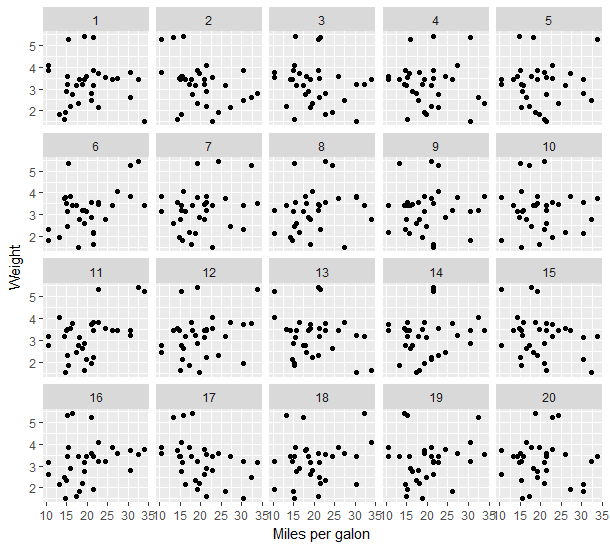
Jelikož ale nejsme specialisté na to, jak mohou vypadat náhodně generovaná data (za platnosti nulové hypotézy), je třeba nejprve „nakalibrovat oči“ na přirozenou varianci – právě k tomu slouží tzv. Rorschachův protokol. V našem případě bychom se tedy nejprve před samotným „testovaním“ podívali na různá náhodná data. Ty můžeme vidět v následujícím obrázku. Kolik tam vidíte zajímavých vztahů? Nebo to je vše přibližně podobné?
Pro více informací doporučujeme článek od Wickhama, Cookové, Hofmannové a Buji (2010). Použití těchto metod oproti klasickým testům validizoval Mahbubul Majemder ve své dizertační práci či v následných článcích (např. Majumder, Hofmann, & Cook, 2013).
Odpověď na první otázku je graf č. 6.
17/6/2018 (mp, fd)
Zdroje
CRAN R Project. Dostupné z: https://cran.r-project.org/web/packages/nullabor/vignettes/nullabor.html
Majumder, M., Hofmann, H., & Cook, D. (2013). Validation of visual statistical inference, applied to linear models. Journal of the American Statistical Association, 108(503), 942-956.
Wickham, H., Cook, D., Hofmann, H., & Buja, A. (2010). Graphical inference for infovis. IEEE Transactions on Visualization and Computer Graphics, 16(6), 973-979.
Wickham, H., Chowdhury, N. R., & Cook, D. (2012). nullabor: Tools for graphical inference. R package version 0.2, 1, 213.
Poznámky
S grafy se pak v R dá dále pracovat. Lze tak kupř. spočítat rozdíl mezi vaší testovou statistikou a ostatními vygenerovanými statistikami (průměrné rozdíly mezi lineupy). V případě, že průměrná vzdálenost hodnot těchto generovaných statistik dosahuje nižších hodnot než průměrná vzdálenost hodnot reálné testové statistiky, pak seřazení považujeme za ucházející (easy lineup naproti neucházejícímu – difficult lineup).